What is Memory Model?
So, when we talk about the memory model, what exactly are we talking about? Well, to find out, we need to dig into it.
There are two main aspects to the memory model: one is Structural, and the other is Concurrency.
And we can’t really talk about concurrency without understanding how data is laid out in memory.
In C++ it’s all about objects and memory locations
Now, when we say object, we’re not talking about classes or structs the way they’re defined in languages like Java.
According to the C++ standard object is simply “a region of
storage.” Alright, now we get that an object
can be a simple value of a fundamental type like int, or an instance of a user-defined class.
Great. Now let’s say we define a struct like the one below. The question that might come to your mind is: which part is
considered the object? And if every variable is treated as an object, then how exactly do they get stored in memory?
By the way, I borrowed the diagram from
C++ Concurreny in Action.
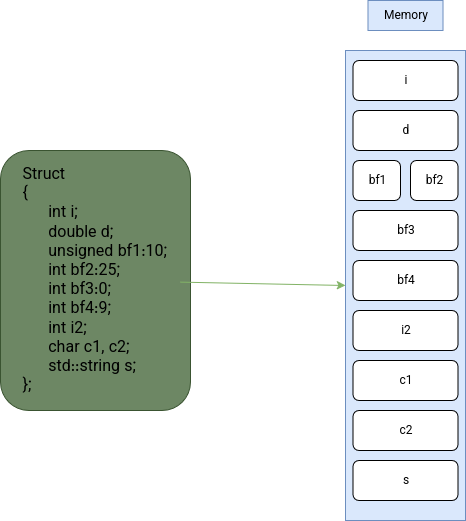
From the diagram we can see a few key things: every variable is an object, and each object of a fundamental type occupies exactly one memory location regardless of its size (But how?). And, last but not least adjacent bit fields share the same memory location.
So, here’s question Why do fundamental type objects occupy exactly one memory location? well, because memory location doesn’t mean 1byte, it can span multiple bytes. It’s a logical concept that defines the object’s identity and its uniqueness in terms of storage.
int x = 2;
Here x takes up 4 bytes on a 32-bit system, but it still counts as one memory location, the storage region
stating at its address and spanning 4 bytes. Alright, now about bit fields. In the diagram, we can see the
zero-length bit field causes the next bit field to go to a different memory location, but why?
The special unnamed bit-field of size zero can be forced to break up padding. It specifies that the next bit-field begins at the beginning of its allocation unit
That’s straight from the C++ standard. It basically gives a programmer control over alignment and memory
layout. Why should we care? Great question! In concurrent programming memory layout starts to matter (a lot).
We might want to ensure that two fields are on separate memory locations to prevent some surprises like false sharing.
Here’s a simple example:
1struct Flags {
2 unsigned int a : 1;
3 unsigned int b : 1;
4 unsigned int c : 1;
5};
6
7int main()
8{
9 Flags fl;
10 fl.a = 1;
11 fl.b = 0;
12 fl.c = 1;
13
14 return 0;
15}The compiler turns this into something like:
1 movzx eax, BYTE PTR [rbp-4]
2 or eax, 1
3 mov BYTE PTR [rbp-4], al
4 movzx eax, BYTE PTR [rbp-4]
5 and eax, -3
6 mov BYTE PTR [rbp-4], al
7 movzx eax, BYTE PTR [rbp-4]
8 or eax, 4
9 mov BYTE PTR [rbp-4], alBefore diving in, let’s remember a few things:
rbp1is the base pointer for the current stack frame.[rbp-4]refers to a local char variable on the stack.eaxis a 32-bit general purpose register;alis its lower 8 bits.
Now let’s go step by step:
movzx eax, BYTE PTR [rbp-4]Loada byte from[rbp-4]into eax, zero extending to 32 bitsmovzxmeans: move byte -> extend to 32-bit eax with zero fill- Now
eaxcontains the 8-bit value of the variable at[rbp-4]
or eax, 1Setbit0to1(OR with00000001)- So this sets the lowest bit of the byte to
1
mov BYTE PTR [rbp-4], alStorethe lower 8 bits of eax (al) back into[rbp-4]- This commits the bit-0 set operation to memory
movzx eax, BYTE PTR [rbp-4]Loadthe modified byte again from[rbp-4]intoeax
and eax, -3-3is0xFFFFFFFD, which in binary is11111111 11111111 11111111 11111101ANDingwith this clears bit1(second least significant bit), but leaves all others unchanged
mov BYTE PTR [rbp-4], alStorethis new value (bit1cleared) back into memory
or eax, 4ORwith00000100= set bit2
So, what does it show exactly? Every read and write is to the same memory address: BYTE PTR [rbp-4],
That means all three bit fields a, b, c are packed into a single byte. They share the same memory location.
Now let’s throw in a twist:
1struct Flags {
2 unsigned int a : 1;
3 unsigned int : 0;
4 unsigned int c : 1;
5};This time, the compiler generates:
1 movzx eax, BYTE PTR [rbp-8]
2 or eax, 1
3 mov BYTE PTR [rbp-8], al
4 movzx eax, BYTE PTR [rbp-4]
5 or eax, 1
6 mov BYTE PTR [rbp-4], al
7 mov eax, 0a is stored at [rbp-8] and c at [rbp-4]. The unnamed zero-length bit field between them broke the
memory sharing, forcing c to start in a new location.Wrapping Up
So, what did we learn here?
- Every object in C++ occupies one logical memory location even if it’s several bytes wide.
- Bit fields can share memory if they’re next to each other, but a zero-length bit field acts like a wall, forcing the next field into a new memory spot.
- And all of this matters a lot more than it seems especially in concurrent programming, where memory layout can make or break performance (or correctness).
We’re just scratching the surface here. In upcoming parts, we’ll look at how the memory model affects thread interactions, atomic operations, and those sneaky data races.
Thanks!